Database and Data Provenance
Why and Why-not Provenace Summaries for Queries with Negation
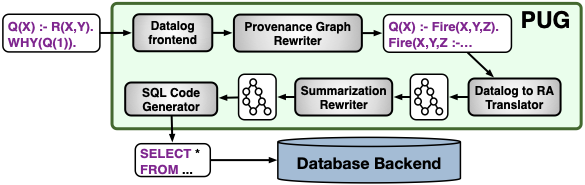
Provenance explains produced data over database operations such that which tuple (row) in the data generated by a query is derived from which tuple in the input data through which operation(s). Similarly, why-not provenance informs why and how tuples are missing in the produced data. PUG (Provenance Unification through Graphs) is a middleware system that efficiently captures provenance for a given data and query. PUG introduces a novel approach for computing unified why and why-not provenance. The technique used in PUG is the first practical method that computes explanations using samples of why-not provenance over real-world datasets and queries with negation. The system is (particularly) useful for understanding processed data, debugging data processing pipelines, and so on. In the following, research (including development) opportunities which add more power to PUG are listed.
Efficient Sampling for Big Provenance
Provenance has been studied extensively to explain existing and missing results for many applications while focusing on scalability and usability challenges. Recently, techniques that efficiently compute a compact representation of provenance have been introduced. In this work, we introduce a practical solution that computes a sample of provenance for existing results without computing full provenance. Our technique computes a sample of provenance based on the distribution of provenance wrt the query result that is estimated from the distribution of input data while considering the correlation among the data. The preliminary evaluation demonstrates that comparing to the naive approach our method efficiently computes a sample of (large size of) provenance with low errors. The initial paper is available here.
Hybrid Explanations and Repairs
Prior work on explaining missing (unexpected) query results identifes which parts of the query or data are responsible for the erroneous result or repairs the query or data to fx such errors. The problem of generating repairs is typically expressed as an optimization problem, i.e., a single repair is returned that is optimal wrt. to some criterion such as minimizing the repair’s side efects. However, such an optimization objective may not concretely model a user’s (often hard to formalize) notion of which repair is “correct”. In this paper, we motivate hybrid explanations and repairs, i.e., that fix both the query and the data. Instead of returning one “optimal” repair, we argue for an approach that empowers the user to explore the space of possible repairs efectively. We also present a proof-of-concept implementation and outline open research problems. The initial paper is available here
Applications of Data Management and Data Provenance
Provenance-based ML Explanations
This project develops a generic tool, which we call Generic Provenance-based System for Machine Learning (GPML), designed to facilitate explainable ML through provenance. In the context of an ML task, GPML efficiently captures provenance and generates explanations during the model training process. Our framework achieves this by transforming the given ML model into a Datalog program, a logic-based declarative database query language, utilizing and expanding formal semantics to accommodate a broad range of ML models, including neural networks. The provenance component within GPML efficiently captures provenance by enhancing previous techniques through the rewriting of the Datalog program. The resulting provenance is comprehensive enough to compute more detailed (explaining the impact of subsets of features and data instances) and unified (providing both global and local) explanations. The explanation generation component of GPML will then produce these explanations based on the captured provenance, eliminating the need for model retraining. GPML’s output comprises a set of explanations detailing the contributions of (sub- populations of) features and data instances, in addition to the model’s prediction. The initial work of this research project is outlined here.
Exploring Provenance for Explainable Information Gain
In recent years, a large amount of data is collected from multiple sources and the demands for analyzing these data have increased enormously. Data sharing is a valuable part of this data-intensive and collaborative environment due to the synergies and added values created by multi-modal datasets generated from different sources. In this work, we introduce a technique that quantifies the degree of information gain (IG) that is obtained over data sharing. The IG is computed based on the distance between data that are integrated after the sharing. Our method captures both where (to compute the IG over values) and how provenance (to find matching records) and accurately computes the IG based on them. To provide better understanding on the data sharing, we develop a technique that computes meaningful summaries of data that highly contribute to IG. For that, we define four metrics that allow to provide such meaningful explanations. We conduct a set of experiments to demonstrate the performance and accuracy of our approach comparing to naive method using real-world datasets. The initial version of the paper is available here.